kafka streams 是什么 Kafka 号称是一个开源的分布式流数据处理平台,其除了提供基本的 Consumer api 和 Producer api 用于处理基本的消费和生成数据外,还抽象和封装了功能更强大的 Streams api 用于实现基于 kafka 的流式计算。不同于flink、spark 等其他框架,kafka streams 仅仅是一个 java library,但通过深度结合 kafka 的种种高级特性,实现了一个轻量级、功能完备的流式计算框架, kafka streams 承载着 kafka 在流计算领域大展拳脚的野心,也逐渐成为 kafka 项目越发重要的组件。
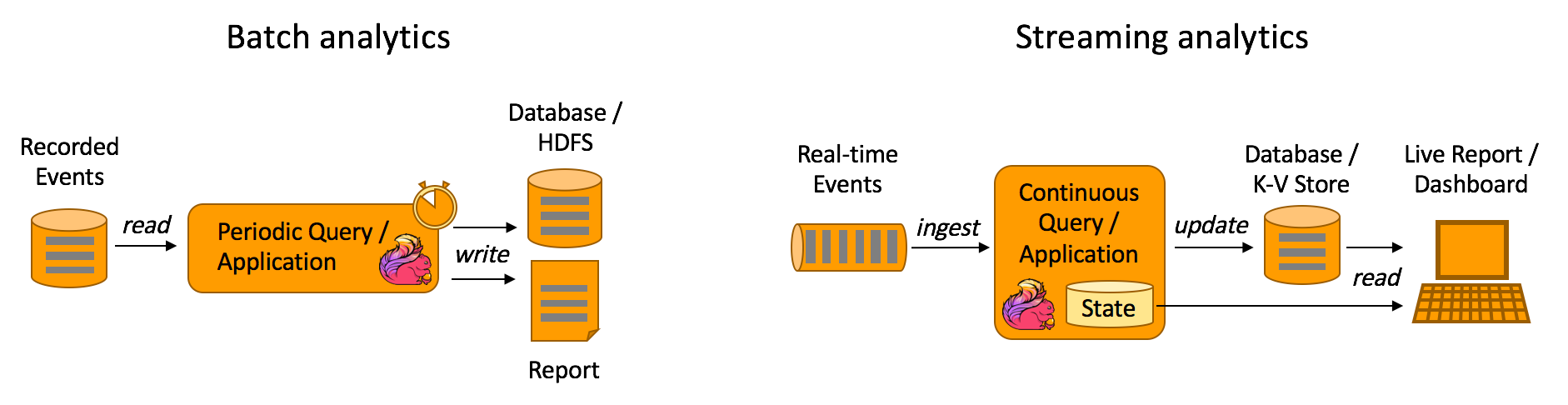
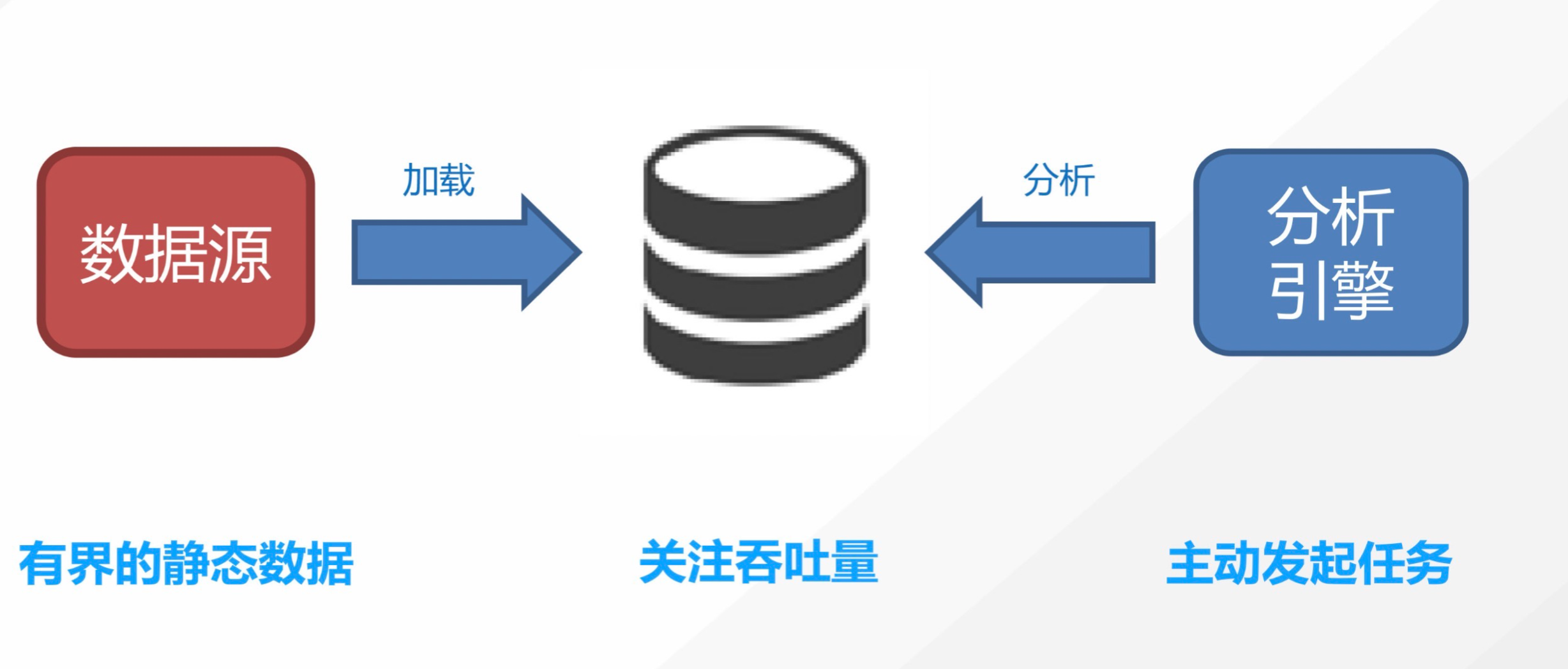
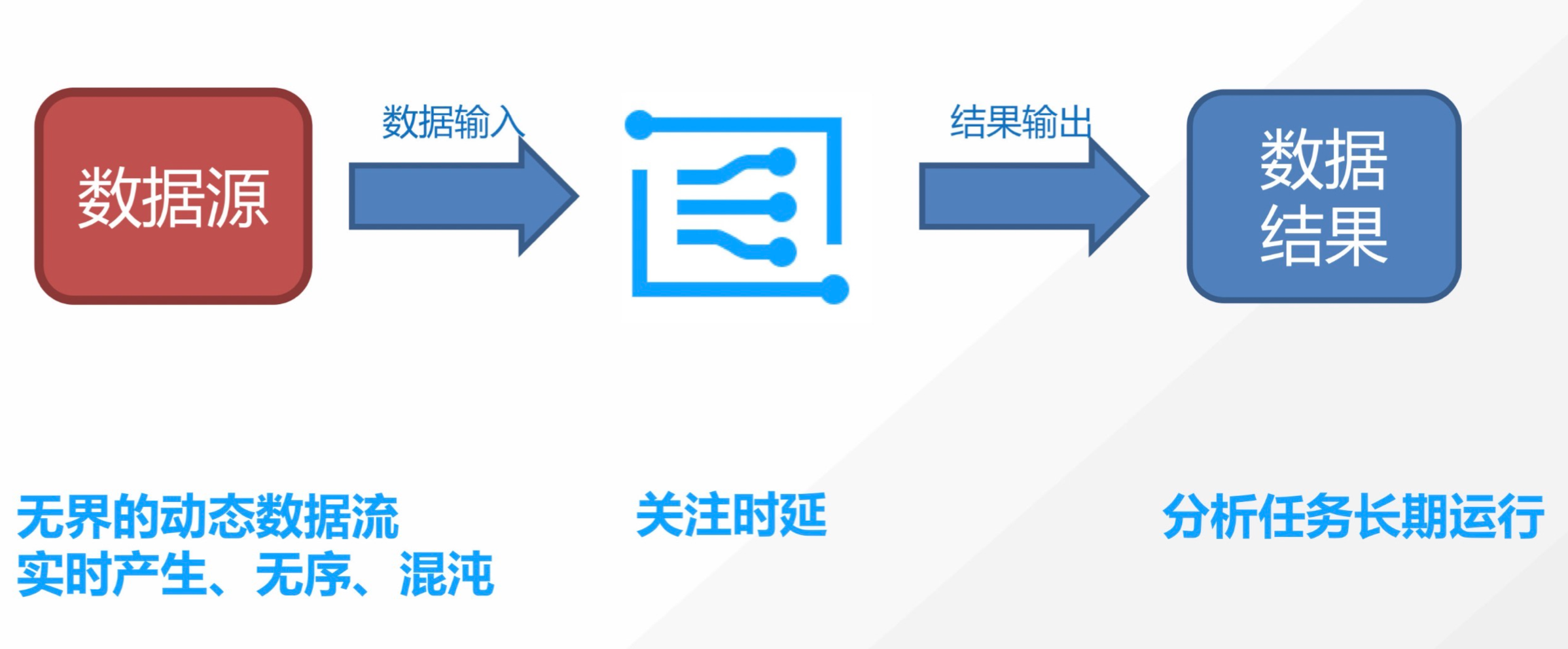
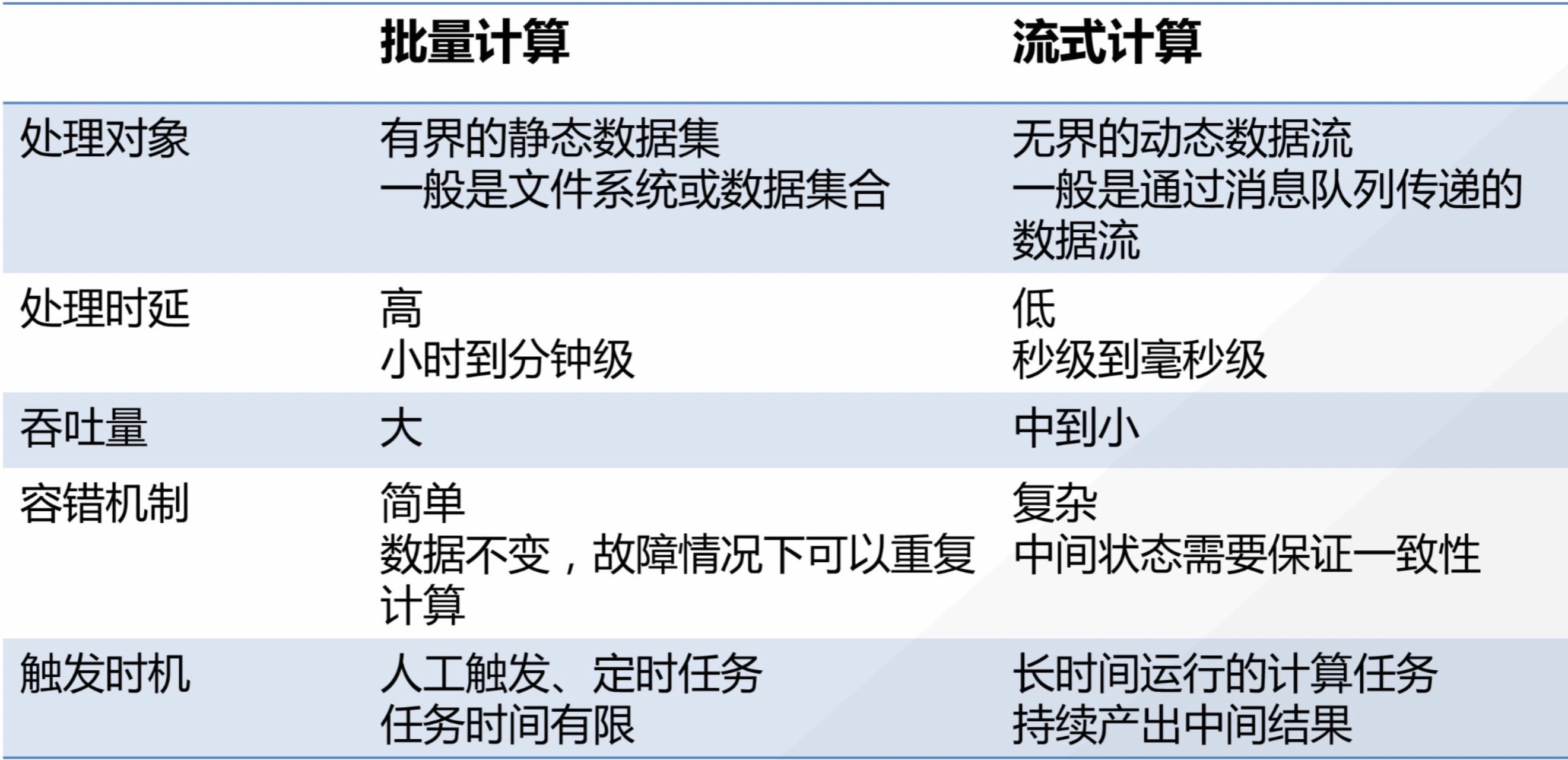
流计算简介 借用 flink 官网的一张批量计算和流计算的图,我们能对二者的用户场景有一个较清晰的认识。
批量计算
流式计算
典型的批量计算场景如获取去年的用户地域分布情况,典型的流计算场景如阿里双11的实时成交额。
kafka streams kafka streams 是 kafka 提供的一个 api library, 类似于Producer api 和 Consumer api, kafka streams 实时消费上游的 topic,经过自定义的计算,将结果生产到下游的 topic,理论上你可以自己写调用 Producer api 和 Consumer api来实现一个流计算应用,那与之相比, kafka streams 的优势在哪呢?
流计算不仅仅是 consume + produce: 流计算框架更贴近业务,其抽象了诸多概念如时间定义(生成时间、处理时间、事件时间)、时间窗口(sliding window、hopping window、event window等)、处理晚到数据、map-reduce、table join 等标准功能,使用底层api 实现会费时费力,且不可复用。
流计算需要状态和执行语义保证: 大部分的流计算任务都是有状态的,部分计算任务也是有exactly-once 等语义保证的。使用底层api 比较难统一的抽象存储和实现保证的语义。
因此可以这样理解 kafka streams,kakfa streams 是一个用于实现流计算任务的 java library, 它底层使用了Producer api 和 Consumer api,并封装了 Time、TimeWindows、StateStore、Kstreams Ktable、Topology 等高级对象对流计算任务进行了完整的抽象,也完整地支持了 exactly-once等语义。
kafka streams 同其他流计算框架对比 相比storm、spark streaming、flink 这些流计算框架,kafka streams 有何特点呢?
轻量。Kafka Streams 仅仅是一个 java Library,它可以非常方便地嵌入任意Java应用中,也可以任意方式打包和部署
依赖少。 运行kafka stream 实现的流计算任务,仅需要 kafka
完备的流计算语义。如支持EventTimeWindow,支持处理晚到的数据,支持 Stream 和 Table 的抽象、支持 exactly-once等
充分利用Kafka分区机制实现水平扩展和顺序性保证
kakfa streams 示例: WordCount 我们以一个kafka streams 的入门示例 WordCount 来进行后续 kafka streams 原理的深入介绍,此处只简单描述下该示例的功能。 这个实例实现了单测计数的功能,用户往 streams-plaintext-input 里持续写入一些句子,运行该应用后,会在WordsWithCountsTopic 中持续输出单词计数的变化。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import org.apache.kafka.common.serialization.Serdes;import org.apache.kafka.common.utils.Bytes;import org.apache.kafka.streams.KafkaStreams;import org.apache.kafka.streams.StreamsBuilder;import org.apache.kafka.streams.StreamsConfig;import org.apache.kafka.streams.kstream.KStream;import org.apache.kafka.streams.kstream.KTable;import org.apache.kafka.streams.kstream.Materialized;import org.apache.kafka.streams.kstream.Produced;import org.apache.kafka.streams.state.KeyValueStore;import java.util.Arrays;import java.util.Properties;public class WordCountApplication public static void main (final String[] args) throws Exception Properties props = new Properties(); props.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-application" ); props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092" ); props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass()); props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass()); StreamsBuilder builder = new StreamsBuilder(); KStream<String, String> textLines = builder.stream("streams-plaintext-input" ); KTable<String, Long> wordCounts = textLines .flatMapValues(textLine -> Arrays.asList(textLine.toLowerCase().split("\\W+" ))) .groupBy((key, word) -> word) .count(Materialized.<String, Long, KeyValueStore<Bytes, byte []>>as("counts-store" )); wordCounts.toStream().to("streams-wordcount-output" , Produced.with(Serdes.String(), Serdes.Long())); KafkaStreams streams = new KafkaStreams(builder.build(), props); streams.start(); } }
运行的效果如下所示:
向 streams-plaintext-input 写入数据
1 2 3 4 > bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic streams-plaintext-input all streams lead to kafka hello kafka streams join kafka summit
从streams-wordcount-output 消费结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 > bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \ --topic streams-wordcount-output \ --from-beginning \ --formatter kafka.tools.DefaultMessageFormatter \ --property print.key=true \ --property print.value=true \ --property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \ --property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer all 1 streams 1 lead 1 to 1 kafka 1 hello 1 kafka 2 streams 2 join 1 kafka 3 summit 1
完整的实例请参考:https://kafka.apache.org/31/documentation/streams/quickstart)
这个例子实现了一个可横向扩展的、错误容忍、有状态的流计算任务,后续内容会基于此例子进行深入的介绍。
kafka streams 的架构
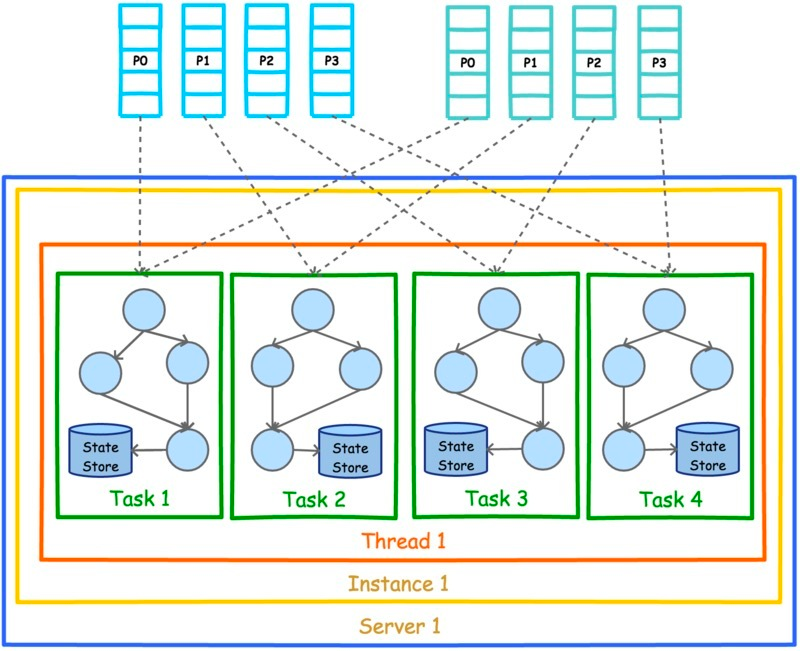
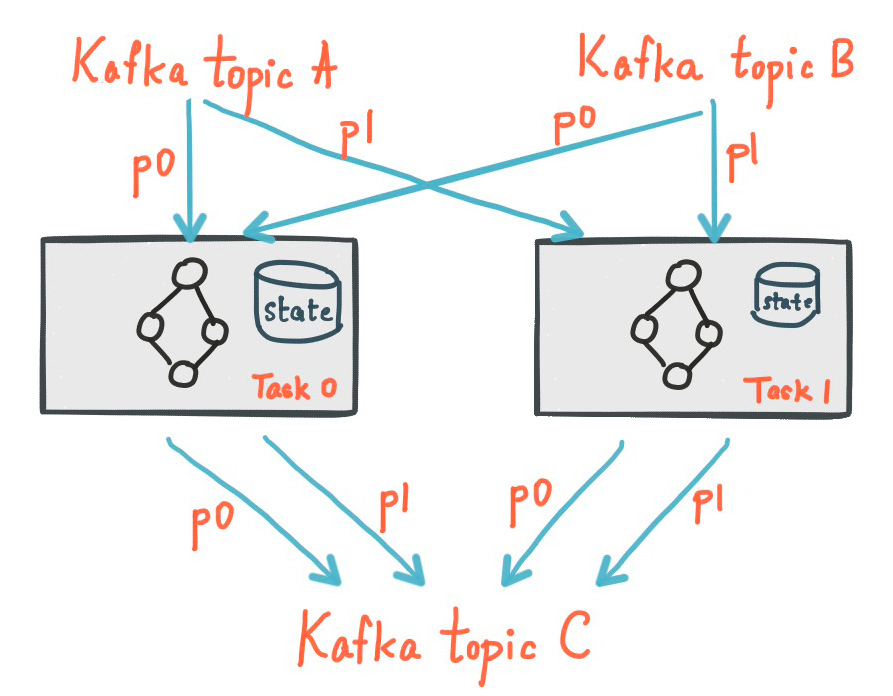
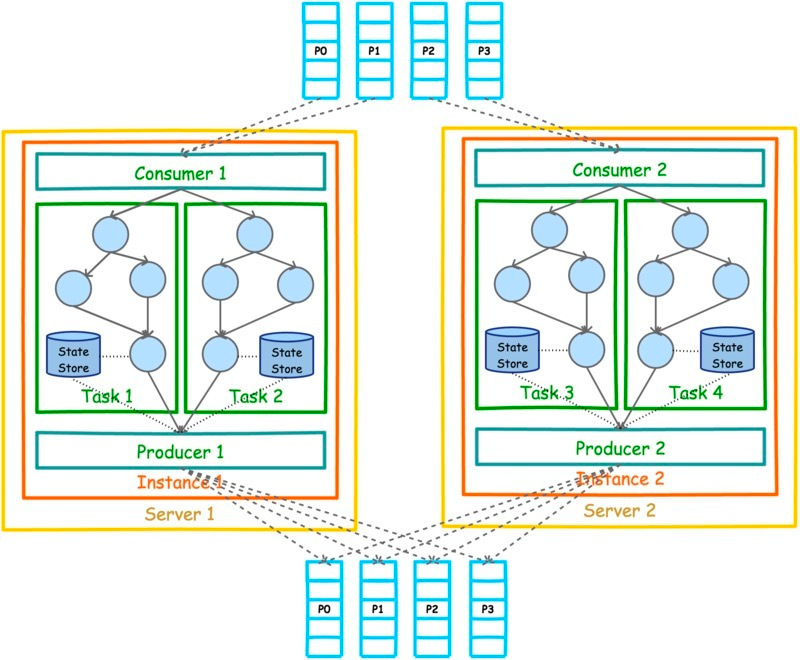
kafka streams 运行的一个示例如上图所示,最上方是streams-plaintext-input,有 4 个 partition,最下面是streams-wordcount-output, 也是 4 个 partition,中间可以理解为单台机器上的一个 java 程序,运行了 WordCount,设置以2个 thread来运行。 定义kafka 地址,input topic 和 output topic 的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 // 定义 kafka streams 的 appid, 会基于其生成 consumer group id props.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-application"); // kafka broker 地址 props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092"); ... // 读取 kafka streams 的 input topic KStream<String, String> textLines = builder.stream("streams-plaintext-input"); ... // 将输出结果写入 output topic wordCounts.toStream().to("streams-wordcount-output", Produced.with(Serdes.String(),
每个 thread 里有以下内容:
一个 consumer 和 producer,用于消费上游数据和将计算结果写入下游数据。
各有2个 task,每个 task 拥有相同且彼此独立的有向无环图,有向无环图图描述了流计算的具体逻辑,每个 task 有独立的 state store 用来存储计算产生的状态数据。
有 4 个 task 是因为上游有4 个 partition,每个 task 负责处理一个 partition的数据。
并发模型 上述实例展示了单实例多线程的运行情况。一般分布式计算任务较大时很难通过单个任务完成,kafka streams 应用是如何实现自动扩缩容的呢?
kafka streams 充分利用了 kafka 的 consumer group 机制,能动态感知 consumer 的变化,针对节点数、kafka streams 实例数、线程数的变化进行tasks 的分配,以实现无缝的扩缩容。
缩容 单节点单实例单线程: 由唯一的线程处理 4 个 tasks。
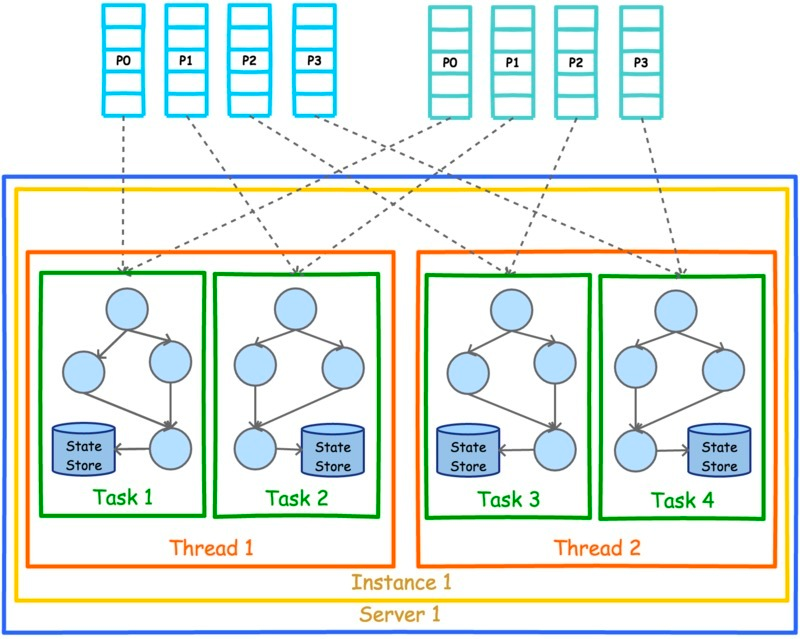
扩容 单节点单实例多线程: 4 个 tasks 平均地分配给 2 个 thread。
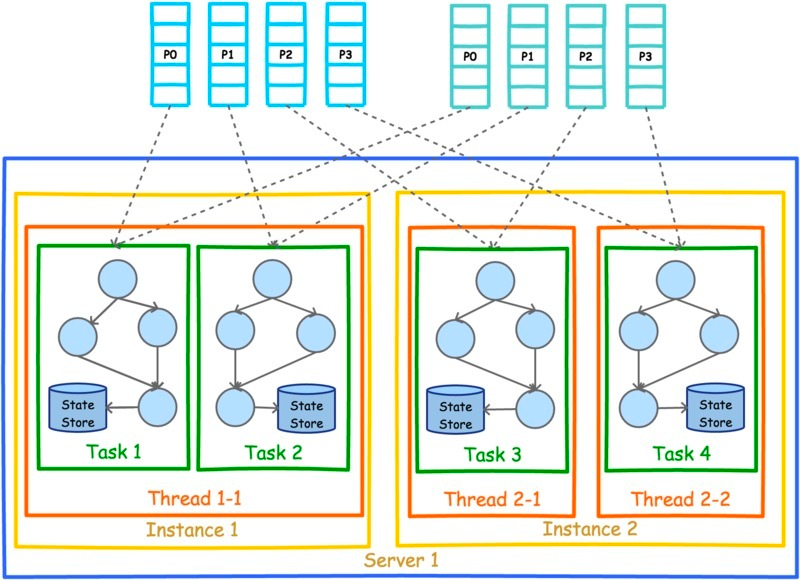
单节点多实例多线程: 4 个 tasks 分配给 2 个 kafka streams 实例的 3 个 thread
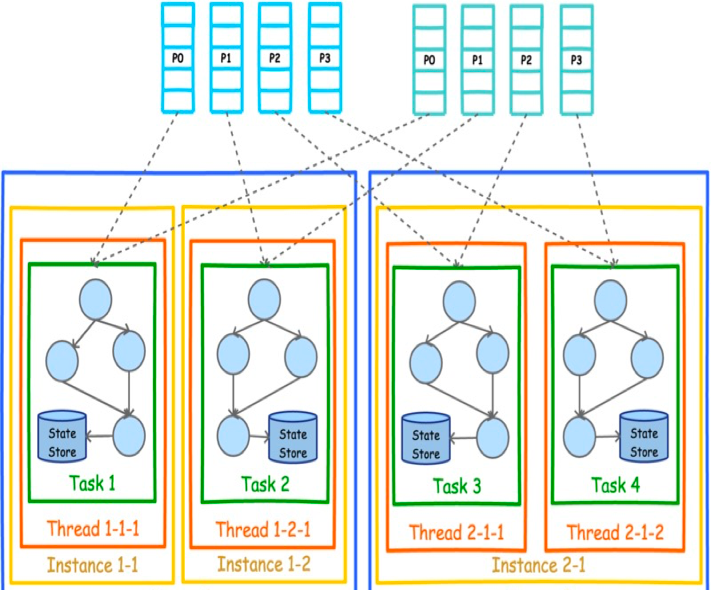
多节点多实例多线程: 4 个 task分配给 4 个 kafka streams 实例,这4个实例分布在 2 个 节点上。
动态分配 tasks kafka streams 还支持动态的 tasks 分配,假如从已运行的多个 kafka streams 实例中删除一个实例,其他的 kafka streams 实例会接管其分配的 tasks,重建 state store,并继续执行。 正是这种无缝动态扩缩容的机制赋予了kafka streams 灵活的部署方式,能根据实际的计算资源进行动态的适配。而且能够以部署无状态服务的方式部署 kafka streams 应用。
限制 最大扩容数:
由于上游topic 的 partition 数量和 tasks 数量是一一对应的,因此最大分配的 tasks 数量是固定的,当kafka streams 实例数超过 tasks 数量时,多余的kafka streams 实例会由于得不到分配的 tasks 任务而处于 pending 状态。
tasks 重新分配:
tasks 重新分配需要 state store 重建然后才能继续执行 task, 重建 state store 会优先从本地磁盘恢复,若找不到本地磁盘信息则会通过远端 kafka 集群的备份 topic 来重建这些信息,可能会耗时较长。
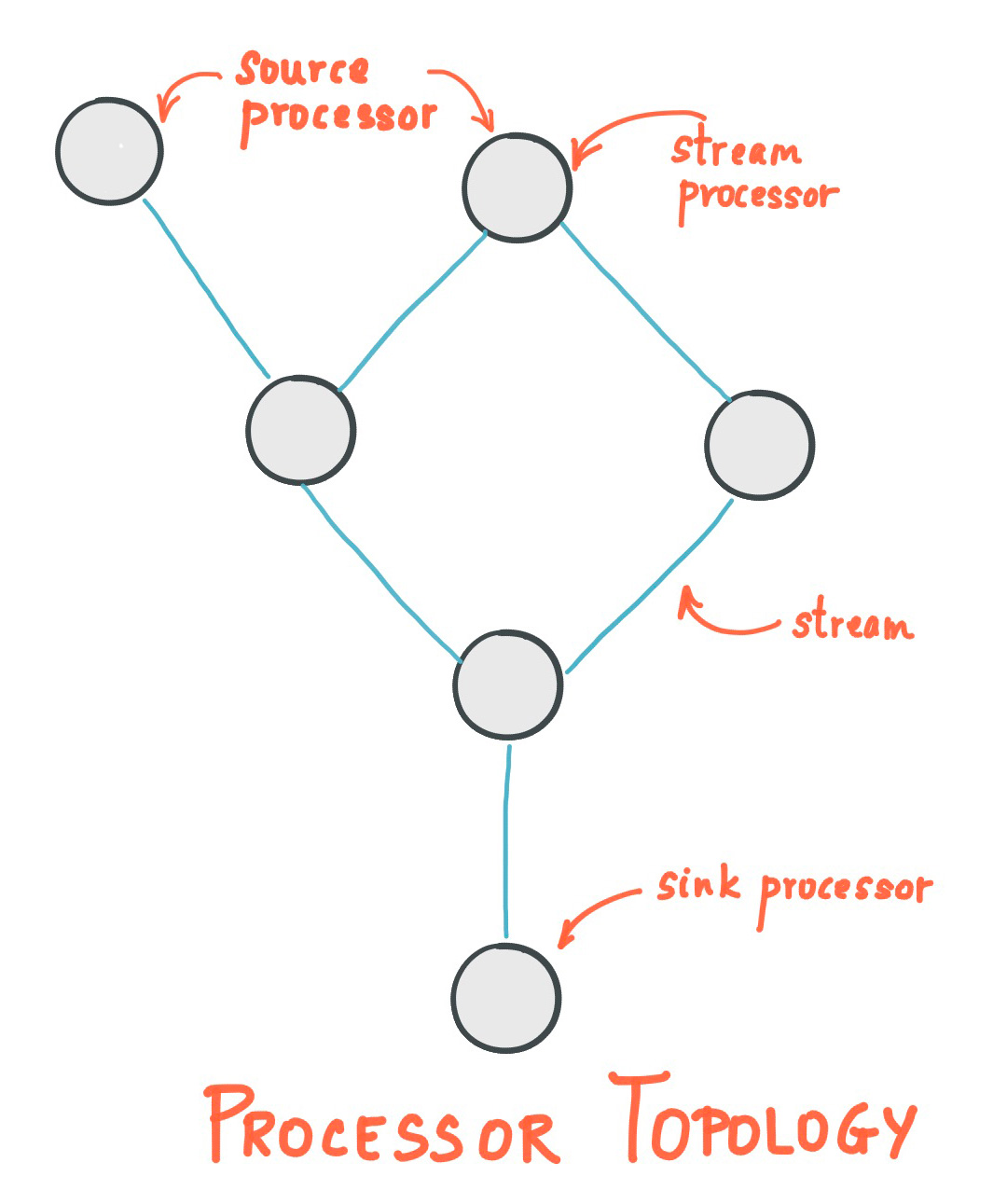
有向无环图(Topology) kafka streams 的 task 的是以有向无环图图(Topology) 的方式进行抽象的,如下图所示
topology 中 processor 有两种比较特殊
source processor: 定义了 topology 的入口,即从哪些topic 读取数据
1 2 3 4 5 6 7 8 9 10 11 // 初始化一个builder,用于最终生成 topology StreamsBuilder builder = new StreamsBuilder(); // 在 topology 中创建 source processor KStream<String, String> textLines = builder.stream("streams-plaintext-input"); // 描述 topology,会生成各种中间的 steam processor KTable<String, Long> wordCounts = textLines .flatMapValues(textLine -> Arrays.asList(textLine.toLowerCase().split("\\W+"))) .groupBy((key, word) -> word) .count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as("counts-store")); //在 topology 中创建 sink processor wordCounts.toStream().to("streams-wordcount-output", Produced.with(Serdes.String(), Serdes.Long())); KafkaStreams streams = new KafkaStreams(builder.build(), props); streams.start();
打印有向无环图(topology)
kafka streams 支持打印生成的 topology,便于用户能更深入地理解 topology 的细节,示例代码
1 2 3 4 5 6 // 通过 StreamBuilder 生成 有向无环图 final Topology topology = builder.build(); // 打印有向无环图 System.out.println(topology.describe());
一个最简单的 topology (非WordCount)打印结果如下, 从结果可看出 topology 只有两个 processor。
KSTREAM-SOURCE-0000000000: 一个 source processor,从streams-plaintext-input 读取数据
KSTREAM-SINK-0000000001: 一个 sink processor,从KSTREAM-SOURCE-0000000000 拿到数据,并写入streams-pipe-output。
因此这个拓扑图代表的计算任务仅仅是从streams-plaintext-input 读取数据,再写到streams-pipe-output 中,没有进行任何的计算。
1 2 3 4 5 6 7 8 > mvn clean package > mvn exec:java -Dexec.mainClass=myapps.Pipe Sub-topologies: Sub-topology: 0 Source: KSTREAM-SOURCE-0000000000(topics: streams-plaintext-input) --> KSTREAM-SINK-0000000001 Sink: KSTREAM-SINK-0000000001(topic: streams-pipe-output) <-- KSTREAM-SOURCE-0000000000 Global Stores: none
状态存储 在流计算任务中不可避免会使用到状态存储。 如WordCount 的示例中,需要在计算时保存每个单词出现的计数。
Kafka Stream 可以为每个流任务嵌入一个或多个本地状态存储,并且允许开发者通过API的方式进行访问、查询所需要处理的数据。这些状态数据底层默认是基于 RocksDB 数据库实现的,本质其实是在内存的一个 hashmap。 而且状态存储默认支持同步到远端的 kafka broker,以 topic 的方式记录本地存储的 changelog。 当kafka streams 的task 因重建或者动态扩缩容而发生迁移时,若迁移后的kafka streams 实例无法从本地磁盘恢复状态,就会读取下changelog 的topic来重建状态存储。
更多细节可以参考:https://kafka.apache.org/31/documentation/streams/architecture#streams_architecture_recovery
kafka streams 与流计算 类似其他流计算框架,kafka streams 支持通用的流计算语义。如时间、时间窗口、流和表的转换、exectly-once 的执行保证等
时间 kakfa streams 分为 3种时间定义:
Event time: 事件时间。 这也是大多数场景使用的时间。我们希望写入topic 的日志能表述其真正发生的时间,后续做相关计算时需要基于该时间。比如要统计一个用户每天登陆 qq 的次数。 在写入kafka 时可以指定 timestamp 来表述该时间
Processing time:日志在kafka streams 任务中处理时的时间。
Ingestion time: 日志被写进 kafka 的 topic 的时间。
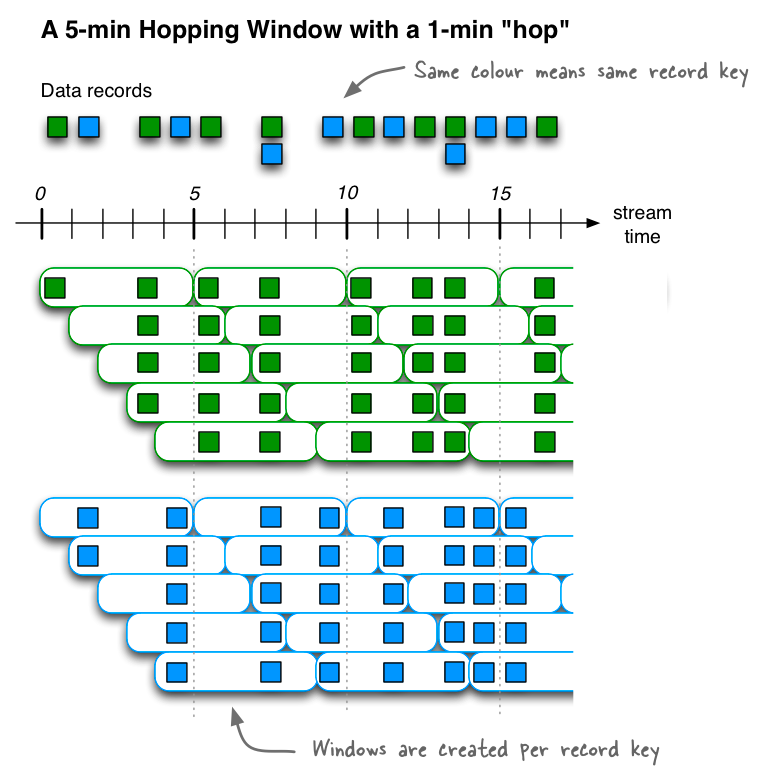
窗口 kafka streams 的 DSL 也提供了多种时间窗口
窗口类型 表现 描述
定义一个大小为5分钟、间隔为1 分钟的Hopping time window。
代码定义
1 2 3 4 5 // A hopping time window with a size of 5 minutes and an advance interval of 1 minute. // The window's name -- the string parameter -- is used to e.g. name the backing state store. Duration windowSize = Duration.ofMinutes(5); Duration advance = Duration.ofMinutes(1); TimeWindows.ofSizeWithNoGrace(windowSize).advanceBy(advance);
Tumbling time window
定义一个大小为5分钟的Tumbling time window。
代码定义
1 2 3 4 5 6 7 8 // A tumbling time window with a size of 5 minutes (and, by definition, an implicit // advance interval of 5 minutes), and grace period of 1 minute. Duration windowSize = Duration.ofMinutes(5); Duration gracePeriod = Duration.ofMinutes(1); TimeWindows.ofSizeAndGrace(windowSize, gracePeriod); // The above is equivalent to the following code: TimeWindows.ofSizeAndGrace(windowSize, gracePeriod).advanceBy(windowSize);
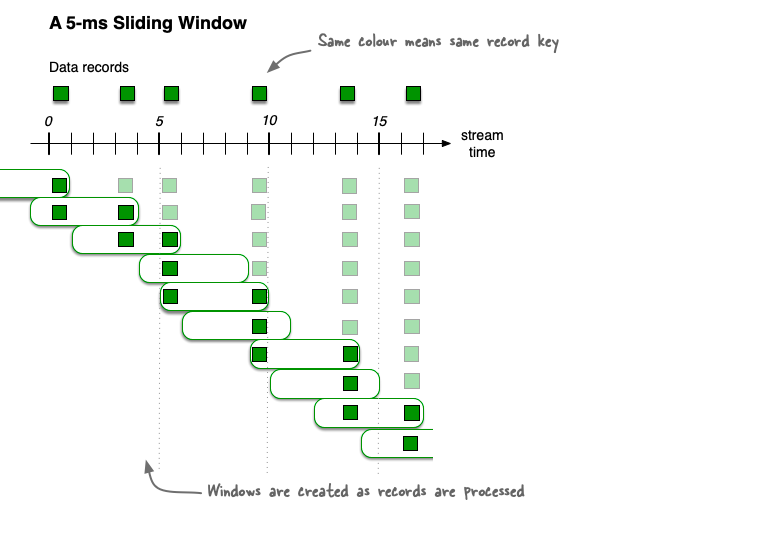
Sliding time windows 主要用于 join 操作,具体可参考:https://kafka.apache.org/31/documentation/streams/developer-guide/dsl-api#sliding-time-windows
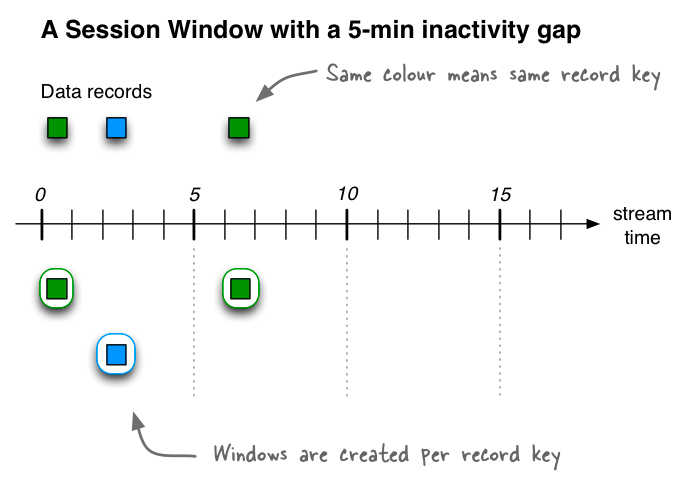
Session Windows: session windows 是窗口固定的、但以事件驱动开始时间的窗口。
定义一个长度为 5 分钟的Session window
1 2 3 4 5 import java.time.Duration; import org.apache.kafka.streams.kstream.SessionWindows; // A session window with an inactivity gap of 5 minutes. SessionWindows.ofInactivityGapWithNoGrace(Duration.ofMinutes(5));
相同的颜色代表相同的kafka 的key,session windows 的开始时间是key 第一次出现的时间。 一个典型的 session window 的使用场景是统计一个网站每个用户的活跃次数。 用户登录及5分钟内的操作认为是一次活跃,则每个 session windows 的开始时间是一次登录日志,这之后五分钟内的任何操作都会认为属于同一次活跃行为。
执行保证 kafka streams 支持 exactly-once,这也是理想的流计算引擎需要支持的功能,这可以保证一条数据写入kafka后,所有的计算都只发生一次。 要实现这样的语义并不容易,因为 kafka streams 的典型场景是 consume + compute + produce, 失败随时都会发生,如从上游消费失败、计算失败、写入下游失败,都会阻碍 exactly-once 语义的实现。
kakfa streams 通过使用 kafka 的一些高级特性实现了在kafka 系统内端到端的exactly-once。 主要使用了如下特性:
producer 写入单个partition的幂等性:即在同一个partition 写入多条相同的数据,只会生效一次
https://www.confluent.io/blog/enabling-exactly-once-kafka-streams/
https://www.confluent.io/blog/exactly-once-semantics-are-possible-heres-how-apache-kafka-does-it/
https://www.confluent.io/blog/simplified-robust-exactly-one-semantics-in-kafka-2-5/
kafka streams 编程模型 kafka streams 的核心是生成有向无环图(Topology)来描述计算任务,它提供了两种编程模型来实现该操作
Processor API 低级别的 api, 需要开发者来描述整个拓扑图的算子,以及定义及使用 state store,上手难度大,灵活性强。
DSL Domain Specific Language,是定义在 Processor API 之上更高级的编程模型,它屏蔽了很多底层实现细节,提供了 Window、Join等高级功能,可以通过 KStream 和 KTable 的各种 map reduce join 的操作来生成执行的 Topology。 本文最上面提供的示例就是使用 DSL 来实现的。当然也可以使用 Process API 来实现,但需要开发者考虑的部分就较多了。
DSL 能满足绝大部分的计算场景。
DSL 和 Processor API 的结合 某些复杂的业务场景可能 DSL 无法满足、或者实现生成的 Topology 比较冗余,也可以结合DSL 和 Processor API 进行更丰富的描述。如下是一个示例,该例子实现了当网页访问的次数超过1000次时发送邮件提醒管理员。Processor 相比仅仅在DSL 中 iterate 每条记录能实现更高级的功能,比如为了避免发送邮件的次数过多,可以在 Processor 里定义一个 state store,仅仅在网页第一次访问超过1000次时进行提醒,之后不再提醒避免邮件告警淹没。 由于 Processor 强大的可扩展性可以很方便地实现上述功能,而这在单纯的DSL里就比较难定义、或者实现的性能较差。
processor 的定义
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 // A processor that sends an alert message about a popular page to a configurable email address public class PopularPageEmailAlert implements Processor < PageId, Long, Void, Void > { private final String emailAddress; private ProcessorContext < Void, Void > context; public PopularPageEmailAlert(String emailAddress) { this.emailAddress = emailAddress; } @Override public void init(ProcessorContext < Void, Void > context) { this.context = context; // Here you would perform any additional initializations such as setting up an email client. } @Override void process(Record < PageId, Long > record) { // Here you would format and send the alert email. // // In this specific example, you would be able to include // information about the page's ID and its view count } @Override void close() { // Any code for clean up would go here, for example tearing down the email client and anything // else you created in the init() method // This processor instance will not be used again after this call. } }
DSL 中使用 processor
1 2 3 4 5 6 7 8 9 KStream < String, GenericRecord > pageViews = ...; // Send an email notification when the view count of a page reaches one thousand. pageViews.groupByKey() .count() .filter((PageId pageId, Long viewCount) - > viewCount == 1000) // PopularPageEmailAlert is your custom processor that implements the // `Processor` interface, see further down below. .process(() - > new PopularPageEmailAlert("alerts@yourcompany.com"));
测试编写
以下是一个Processor API 开发的应用的测试 case
setup 定义了 Topology的描述https://kafka.apache.org/31/documentation/streams/developer-guide/testing.html
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 private TopologyTestDriver testDriver; private TestInputTopic < String, Long > inputTopic; private TestOutputTopic < String, Long > outputTopic; private KeyValueStore < String, Long > store; private Serde < String > stringSerde = new Serdes.StringSerde(); private Serde < Long > longSerde = new Serdes.LongSerde(); @Before public void setup() { final Topology topology = new Topology(); topology.addSource("sourceProcessor", "input-topic"); topology.addProcessor("aggregator", new CustomMaxAggregatorSupplier(), "sourceProcessor"); topology.addStateStore( Stores.keyValueStoreBuilder( Stores.inMemoryKeyValueStore("aggStore"), Serdes.String(), Serdes.Long()).withLoggingDisabled(), // need to disable logging to allow store pre-populating "aggregator"); topology.addSink("sinkProcessor", "result-topic", "aggregator"); // setup test driver final Properties props = new Properties(); props.setProperty(StreamsConfig.APPLICATION_ID_CONFIG, "maxAggregation"); props.setProperty(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "dummy:1234"); props.setProperty(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass().getName()); props.setProperty(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.Long().getClass().getName()); testDriver = new TopologyTestDriver(topology, props); // setup test topics inputTopic = testDriver.createInputTopic("input-topic", stringSerde.serializer(), longSerde.serializer()); outputTopic = testDriver.createOutputTopic("result-topic", stringSerde.deserializer(), longSerde.deserializer()); // pre-populate store store = testDriver.getKeyValueStore("aggStore"); store.put("a", 21 L); } @After public void tearDown() { testDriver.close(); } @Test public void shouldFlushStoreForFirstInput() { inputTopic.pipeInput("a", 1 L); assertThat(outputTopic.readKeyValue(), equalTo(new KeyValue < > ("a", 21 L))); assertThat(outputTopic.isEmpty(), is(true)); } @Test public void shouldNotUpdateStoreForSmallerValue() { inputTopic.pipeInput("a", 1 L); assertThat(store.get("a"), equalTo(21 L)); assertThat(outputTopic.readKeyValue(), equalTo(new KeyValue < > ("a", 21 L))); assertThat(outputTopic.isEmpty(), is(true)); } @Test public void shouldNotUpdateStoreForLargerValue() { inputTopic.pipeInput("a", 42 L); assertThat(store.get("a"), equalTo(42 L)); assertThat(outputTopic.readKeyValue(), equalTo(new KeyValue < > ("a", 42 L))); assertThat(outputTopic.isEmpty(), is(true)); } @Test public void shouldUpdateStoreForNewKey() { inputTopic.pipeInput("b", 21 L); assertThat(store.get("b"), equalTo(21 L)); assertThat(outputTopic.readKeyValue(), equalTo(new KeyValue < > ("a", 21 L))); assertThat(outputTopic.readKeyValue(), equalTo(new KeyValue < > ("b", 21 L))); assertThat(outputTopic.isEmpty(), is(true)); } @Test public void shouldPunctuateIfEvenTimeAdvances() { final Instant recordTime = Instant.now(); inputTopic.pipeInput("a", 1 L, recordTime); assertThat(outputTopic.readKeyValue(), equalTo(new KeyValue < > ("a", 21 L))); inputTopic.pipeInput("a", 1 L, recordTime); assertThat(outputTopic.isEmpty(), is(true)); inputTopic.pipeInput("a", 1 L, recordTime.plusSeconds(10 L)); assertThat(outputTopic.readKeyValue(), equalTo(new KeyValue < > ("a", 21 L))); assertThat(outputTopic.isEmpty(), is(true)); } @Test public void shouldPunctuateIfWallClockTimeAdvances() { testDriver.advanceWallClockTime(Duration.ofSeconds(60)); assertThat(outputTopic.readKeyValue(), equalTo(new KeyValue < > ("a", 21 L))); assertThat(outputTopic.isEmpty(), is(true)); } public static class CustomMaxAggregatorSupplier implements ProcessorSupplier < String, Long > { @Override public Processor < String, Long > get() { return new CustomMaxAggregator(); } } public static class CustomMaxAggregator implements Processor < String, Long > { ProcessorContext context; private KeyValueStore < String, Long > store; @SuppressWarnings("unchecked") @Override public void init(final ProcessorContext context) { this.context = context; context.schedule(Duration.ofSeconds(60), PunctuationType.WALL_CLOCK_TIME, time - > flushStore()); context.schedule(Duration.ofSeconds(10), PunctuationType.STREAM_TIME, time - > flushStore()); store = (KeyValueStore < String, Long > ) context.getStateStore("aggStore"); } @Override public void process(final String key, final Long value) { final Long oldValue = store.get(key); if (oldValue == null || value > oldValue) { store.put(key, value); } } private void flushStore() { final KeyValueIterator < String, Long > it = store.all(); while (it.hasNext()) { final KeyValue < String, Long > next = it.next(); context.forward(next.key, next.value); } } @Override public void close() {} }
结语及参考 本文简单介绍了下 kafka streams 的基本概念、实现架构和简单使用,kakfa streams 本身提供了功能完备的流计算能力,是一款深度结合kafka 的轻量级的流式计算引擎。
以下是一些参考资料
 kafka streams 运行的一个示例如上图所示,最上方是streams-plaintext-input,有 4 个 partition,最下面是streams-wordcount-output, 也是 4 个 partition,中间可以理解为单台机器上的一个 java 程序,运行了 WordCount,设置以2个 thread来运行。 定义kafka 地址,input topic 和 output topic 的代码如下:
kafka streams 运行的一个示例如上图所示,最上方是streams-plaintext-input,有 4 个 partition,最下面是streams-wordcount-output, 也是 4 个 partition,中间可以理解为单台机器上的一个 java 程序,运行了 WordCount,设置以2个 thread来运行。 定义kafka 地址,input topic 和 output topic 的代码如下: