kafka streams 是什么
Kafka 号称是一个开源的分布式流数据处理平台,其除了提供基本的 Consumer api 和 Producer api 用于处理基本的消费和生成数据外,还抽象和封装了功能更强大的 Streams api 用于实现基于 kafka 的流式计算。不同于flink、spark 等其他框架,kafka streams 仅仅是一个 java library,但通过深度结合 kafka 的种种高级特性,实现了一个轻量级、功能完备的流式计算框架, kafka streams 承载着 kafka 在流计算领域大展拳脚的野心,也逐渐成为 kafka 项目越发重要的组件。
流计算简介
借用 flink 官网的一张批量计算和流计算的图,我们能对二者的用户场景有一个较清晰的认识。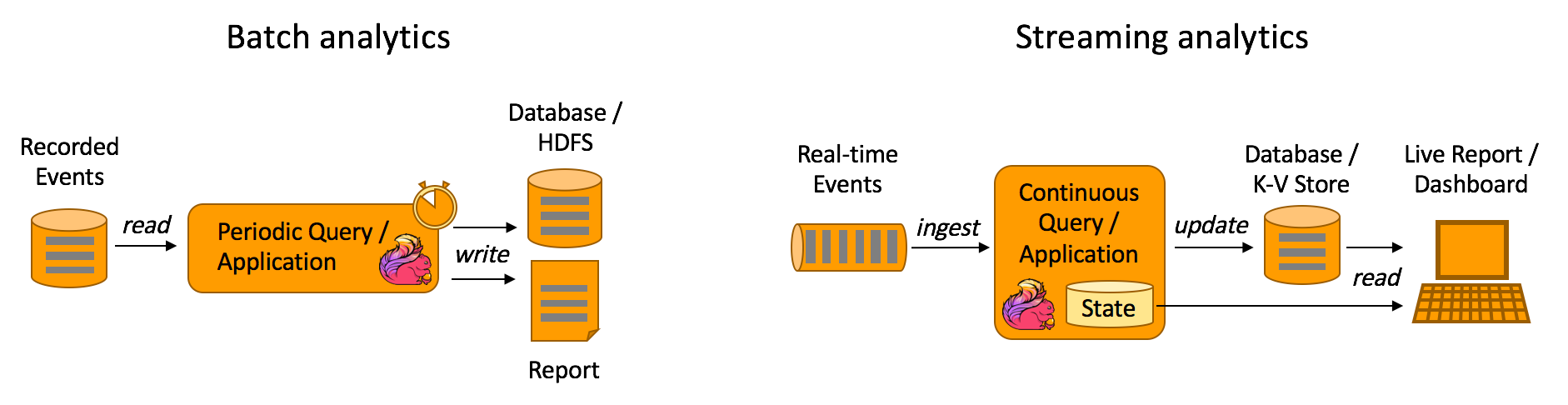
批量计算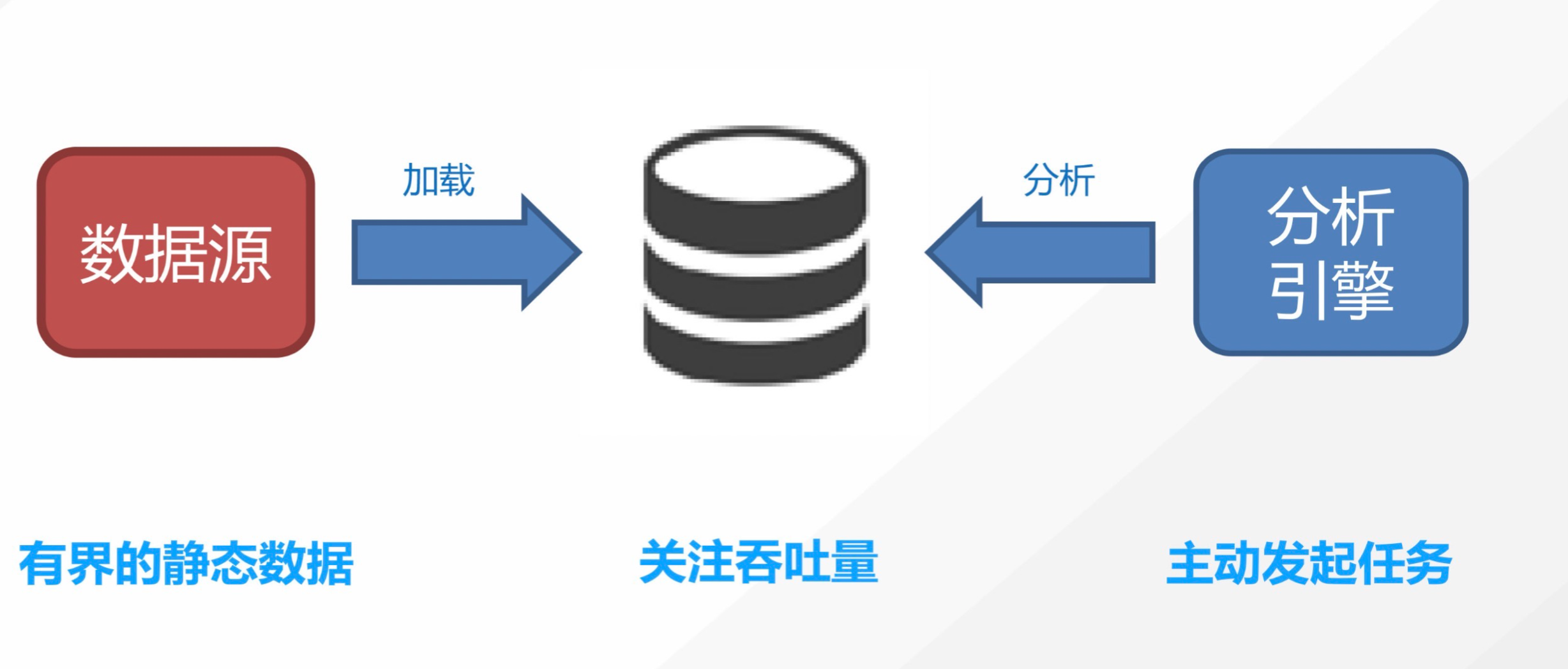
流式计算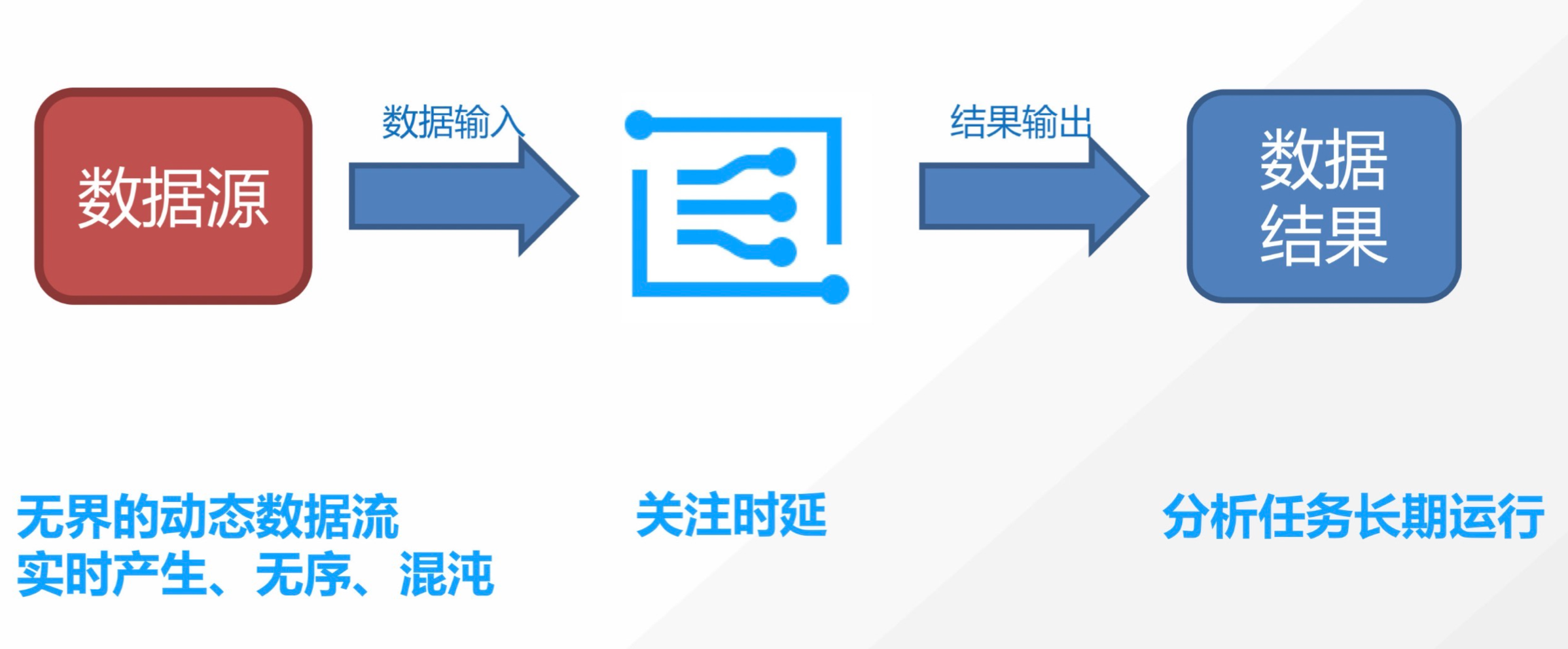
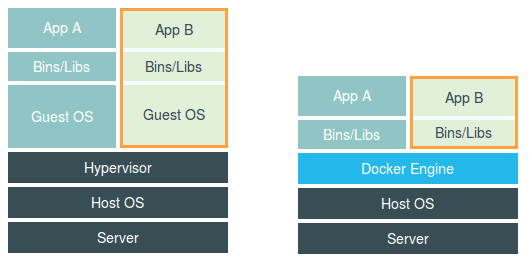
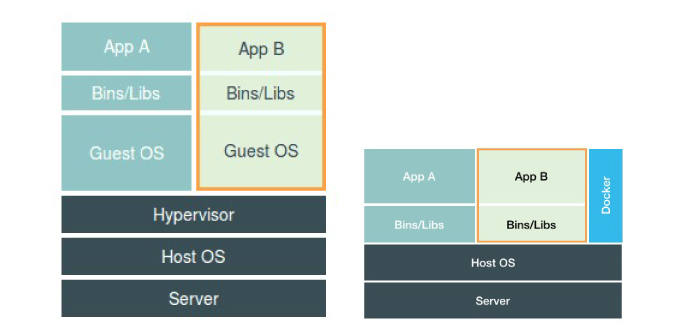 此图中,容器进程直接运行在宿主机上,被宿主机内核管理,docker仅仅起到旁路辅助和管理工作。
此图中,容器进程直接运行在宿主机上,被宿主机内核管理,docker仅仅起到旁路辅助和管理工作。